
The Psychological Impact of Social Media Intelligence on Cyber Analysts
The role of cyber analysts often entails continuous exposure to distressing and harmful content, including violent or explicit material, hate
Published December 2018
We wanted to put out a Bug Info for newer Docker installations that interact with MongoDB. Due to changes in how Docker does its routing it and in some cases ignores IPChains and Firewall settings in certain situations that leads to your MongoDB schema and data being accessible with a MongoDB client from anyone. This Bug results in your MongoDB instance and Schema being accessible to the entire internet! Although there are some posts out (now) there is no real documentation that this is a bug of the new Docker system (unless I forgot something).
We are suggesting that ALL customers, Partners and Friends are aware of this and that you immediately recheck these installations as we can tell you from our experience that this IS a bug and we experienced this while copying over OSINT information into other systems.
The image below shows how you can access ANY mongoDB system with this Docker bug even though you have whitelisted IPs and a firewall active! This just goes to show you that you ALWAYS have to verify that your firewall rules and configuration are STILL WORKING after EVERY UPDATE. This happened to us even though we have multiple testing and staging areas (and use them), what this means is that every update must have external access testing to verify that routing and security still works.
We were contacted by a pen testing team which means there are multiple people that are scanning for port 27017 and slurping anything and everything they can find. We decided to use this as a honeypot to see what happens, the results where beyond frightening….
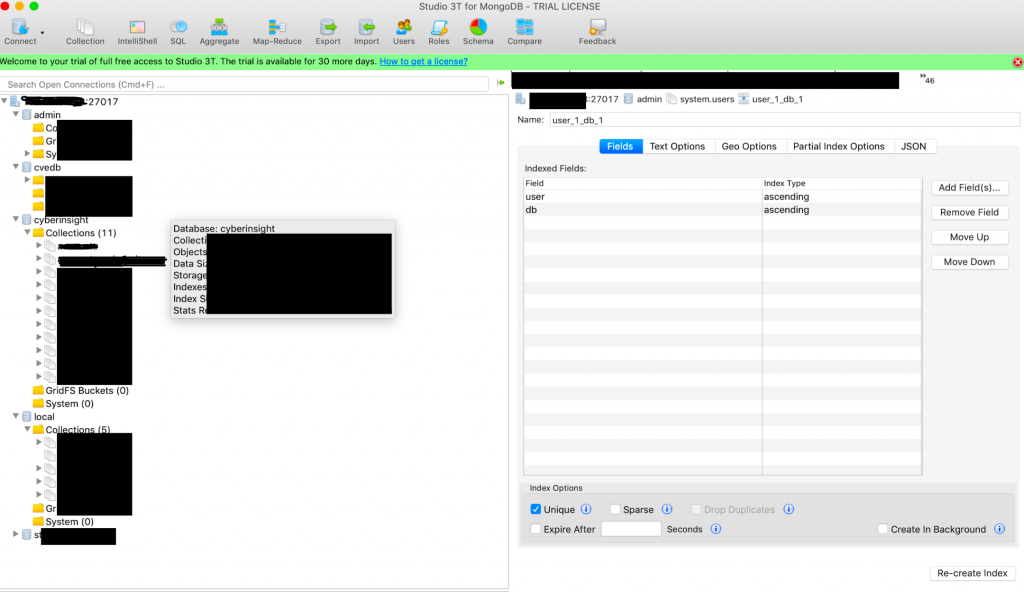
The interesting thing is the fact that we had a firewall that only had 2 whitelisted IPs and everything else blocked using ipchains and opensource firewall solutions (which is the same as most firewalls only less apps running and not on a separate hardware box). That Docker created an update that sidetracked this and didn’t apply the rules correctly which by ignoring the rules opened up the box to this port (27017) and basically let anyone slurp the data from our new server.
So the question that went through my mind was how was this found so quickly and tool sets like nmap and masscan are easy ways to search the entire internet for ports within a few minutes to hours. Using masscan is easy but an attacker has it even easier than ever before thanks to “researchers” at Shodan, Net Systems Research and Censys. The first two sell access to their data to various members and some of them are not cool. Mind you this has nothing to do with hacking but everything to do with getting information quickly. It also means that like so many other companies one of the biggest risks that your mis-configured and openly accessible servers are made fast pwning targets by these services. To be honest I am the first person to be for responsible disclosure but I would argue that this has nothing to do with that. It actually increases the risks of getting attacked and quite honestly its irresponsible with the platform owners don’t regulate access to an extent. When you look at these platforms you also don’t really see tangible warnings to not use the service to hack (which many do). This is important because some issues may actually be discovered before they are exploited but here the playing field is already putting blue teams at a big disadvantage. In addition you have all the complexities of supply chain security that creep up on you during and after EACH NEW UPDATE to ANY APPLICATION or OS. That is a huge risk factor that I would argue shouldn’t really be that way.
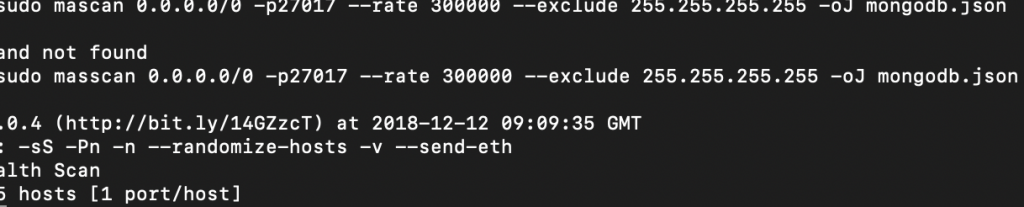
Using Masscan to search for a specific port and the entire internet, then saving the results as (subject).json
We have a lot of processes and documents that show and walk through how we do development, testing, staging and other functions. The objectives are to make sure that errors are checked, rechecked and limited. As I built this company I always told customers that my assumption is we WILL be attacked, hacked, breached at some time so my objective was to limit, separate, segment and implement a least trust model in many areas. This means that we separate many different services, workflows, code, etc. I did this to limit the exposure that I knew that would happen at some point.
When we develop new code we always write everything ourselves and use relevant technology to separate and containerize services into blocks or functions. Some of the best practices teach new developers to use containers because they make more complex systems easier to manage, secure and change. Using technologies that separate services adds security when it works (layer to layer communication) but also adds much more complexity to any given system. In this particular case it actually was the exploit that allowed access from outside because of a bug from that technology that effectively turned off the firewall and whitelisting functions that are an important part of protecting systems while still letting them work with multiple services, use APIs, etc.
Updates and patches are always tested and verified in staging areas or testing environment and I always suggest that people always need to be up to date with OS and Applications because of exploits and threats that constantly emerge from old and new attack vectors. The constant flow of new threats is getting faster and faster which is a change from the past. While we plug in information from CVEs and also Exploit-db, these tools and data are only as good as the relevancy and timeliness of updates to them. We also depend on all the partners in our supply chain to do their work correctly and release documentation of threats or potential risks due to updates quickly. When this information is not released quickly it can become a considerable risk. This specific issue has again verified that supply chain security is vital and that the more technology a company or development team uses, the higher the risks are even when updates and patches are done with that technology. This also in turn means that distrust in all those components needs to be the norm and testing needs to recognize that other partners don’t really do their work correctly all the time.
At the time of writing this we locked down the server (it was a new one that didn’t have all the attack and scan data but it was enough). The experience was painful but also helpful as it highlights issues and challenges of every company whether startup or mature in trusting others in your supply chain to do their work responsibly. The interesting thing is that this error actually confirmed my paranoia in separating authentication information from the data storage (in this case the account data of people using the platform was not viewable here). The only thing that did get slurped was the accounts and other attack data (so I guess this is my present to the world…).
The pro of all this is that all our Darknet, Clearnet and data was not on this server (so again my separation requirements) proved that a breach can be contained by separation. Its great to get that confirmed in an actual honeypot based attack which mimics an actual breach. It also shows me that our approach to multi-dimensional risk and threat theory also stands as multiple attackers (IPs) are actually compromised hosts of other company’s or institutions that had compromised laptops, servers, etc.
What all this means is that breaches and compromised hosts in one area directly influence new threats and risks somewhere else when other threats are actually present in another target. The threats and risks are linked in ways that many don’t really recognize. This fact makes security so damn hard to explain and keep in a consistent state.
So lets spend some time looking at how the attack progressed so that we can use that knowledge to stop future attacks from happening and become more predictive in nature. The way we become more predictive is by using attack data, methodology and also steps so that we can improve those processes to stop the next generation of attacks from happening. So you see I actually eat my own dog food (however painful that sometimes may be). This specific situation has shown that updates and patches can introduce additional risks into a given environment because the trend of bugs in software is increasing rather than decreasing.
Attack Steps:
| 107.170.211.208 | Digitalocean | digitalocean.com | USA | California |
| 107.170.211.235 | Digitalocean | digitalocean.com | USA | California |
| 107.170.216.46 | Digitalocean | digitalocean.com | USA | California |
| 162.243.157.125 | Digitalocean | digitalocean.com | USA | California |
| 119.28.152.64 | Tencent Hosting | tencent.com | Korea | Seoul |
| 185.10.68.129 | Flokinet Ltd | flokinet.is | Island | |
| 185.142.236.34 | BlackHOST Ltd | Shodan.io | Switzerland | |
| 80.82.77.33 | Shodan | Shodan.io | Holland | Amsterdam |
| 185.144.81.231 | M247 Europe | m247.ro | Romainia | |
| 18.209.206.81 | Amazon | Amazon.com | USA | Texas |
| 198.108.66.144 | Censys | Censys.io | USA | |
| 13.90.132.94 | Microsoft | Microsoft.com | USA | Virgina |
| 184.105.139.68 | Hurricane Electric llc | he.net | USA | California |
| 184.105.139.70 | Hurricane Electric llc | he.net | USA | California |
| 184.105.247.252 | Hurricane Electric llc | he.net | USA | California |
| 74.82.47.3 | Hurricane Electric llc | he.net | USA | California |
| 74.82.47.5 | Hurricane Electric llc | he.net | USA | California |
| 216.218.206.69 | Hurricane Electric llc | he.net | USA | California |
| 92.60.188.221 | OVH SAS | ovh.net | France | Roubaix |
| 94.23.220.146 | OVH SAS | ovh.net | France | Roubaix |
| 2.80.130.87 | Highwinds Network Group | stackpath.com | USA | Texas |
| 46.17.101.13 | Highwinds Network Group | stackpath.com | USA | Texas |
| 46.17.101.15 | Highwinds Network Group | stackpath.com | USA | Texas |
| 81.149.97.225 | Highwinds Network Group | stackpath.com | USA | Texas |
| 196.52.43.106 | LogicWeb | netsystemsresearch.com | USA | New Jersey |
| 196.52.43.126 | LogicWeb | netsystemsresearch.com | USA | New Jersey |
| 196.52.43.129 | LogicWeb | netsystemsresearch.com | USA | New Jersey |
| 127.0.0.1 | localhost |
I hope you enjoy this article if you have MongoDB and Docker I would suggest you email me and we can give you access to the block file (or you use this one in the post. At the time of writing we have found over 110K MongoDB servers communicating on port 27017. I suggest you verify and block them quickly.
Update 13.12.18 31 million servers communicating on port 27017
The role of cyber analysts often entails continuous exposure to distressing and harmful content, including violent or explicit material, hate
Definition and Characteristics Stealth attacks refer to malicious activities that involve intrusions into computer systems without detection or raising alarms.